Reducing MySQL Replica Lag by 90% and Lag Catchup time by 97%
Chapter 1: Setting the context
At HomeLane, we have a single MySQL DBMS which acts as both, a data lake and a data warehouse. As one might expect, we schedule ELTs to pull data from our production DB’s into the data lake and then run aggregation jobs to prepare the data for analytics. This aggregated data is then shared with teams via a replica. This architecture keeps things simple and suffices for our use cases. Recently though, we ran into a problem with this setup where we started seeing increased replica lag times. This didn’t abruptly happen in one day but it built over time and reached a point where user experience started to greatly suffer. The result of this increased wait times, sometimes of up to 6 hours, to see updated data which frustrated a lot of users and so this needed to be addressed.
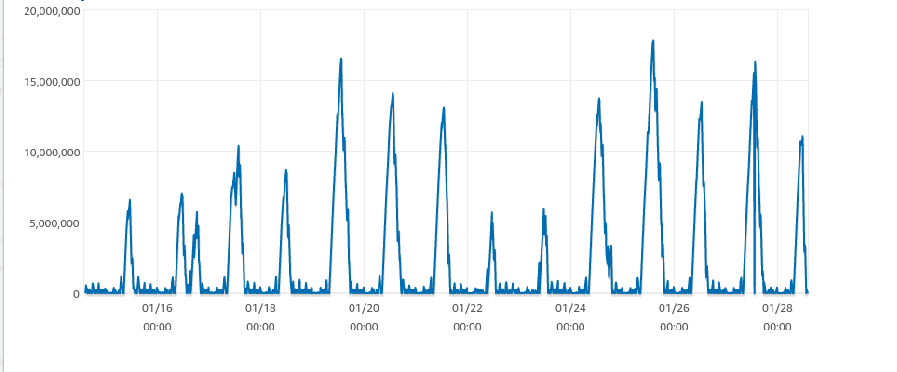 The above image shows the replica lag times. The X-axis represents time while the Y-axis represents replica lag in milliseconds. The beginning and the end of the peaks roughly correspond to 5 am to 1 pm i.e once the lag started, it took 4-5 hours to come back down to acceptable levels.
The above image shows the replica lag times. The X-axis represents time while the Y-axis represents replica lag in milliseconds. The beginning and the end of the peaks roughly correspond to 5 am to 1 pm i.e once the lag started, it took 4-5 hours to come back down to acceptable levels.
After optimizing, the lag looked like this
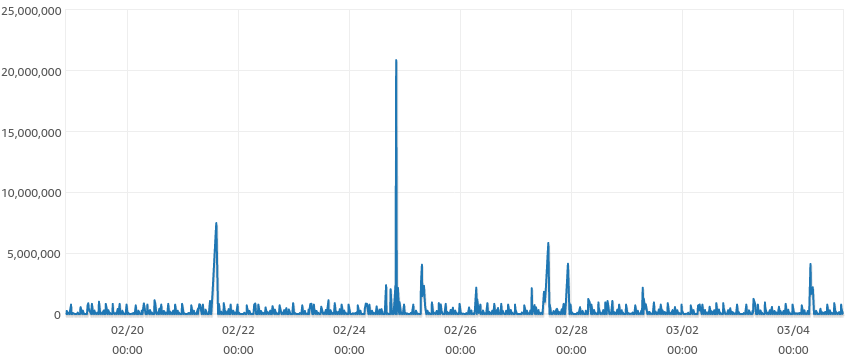 Apart from a few outliers, we were able to reduce the replica lag at any instant to less than 10 minutes and bring down the catchup time significantly from hours to minutes.
Apart from a few outliers, we were able to reduce the replica lag at any instant to less than 10 minutes and bring down the catchup time significantly from hours to minutes.
Chapter 2: Digging deeper
Problem 1:
What I noticed from the initial assessment was how linear the lines of the peaks were. One would expect more dips and plateaus as the replica catches up with the master but instead, the lines were straight, i.e the lag increased linearly with time. This meant that the replica wasn’t replicating anything during this time. On investigating this, it was noticed that this was due to the way the SQL procedures were written. The procedures were written as one big transaction i.e a START TRANSACTION clause at the beginning and a COMMIT at the end. Now according to MySQL docs https://dev.mysql.com/doc/refman/8.0/en/binary-log.html , this would be written as a single atomic operation to the binlog and hence the replica couldn’t replay this until the procedure completed execution on the master. The transactional nature itself of the procedure wasn’t the problem, the execution time of the procedure was. Some procedures that we ran took 30 mins to an hour to complete. This meant that the replica did not replicate anything when the system was under execution and right when the procedure ended the lag shot up by a time equivalent to the procedure execution time. Furthermore, the replication process itself took roughly the same amount of time or greater, and hence the total lag a procedure call created was 2x the procedure execution time. Refactoring the procedure by breaking it into smaller transactions was a solution but we needed a quicker and less error-prone fix for this.
Problem 2:
Another observation was that the replica also replicated the intermediate tables that were used to derive the final table for analytics. This also meant the replica replayed the intermediate calculations which was a waste of time, CPU, and memory as we are only interested in the final table. So this too was something that we wished to resolve.
Chaper 3: Addressing the problems
We began by addressing Problem 2 as it was the most impactful. Our first approach was to configure options to ignore the intermediate tables by configuring --replicate-wild-ignore-table https://dev.mysql.com/doc/refman/8.0/en/replication-options-replica.html#option_mysqld_replicate-wild-ignore-table. We tried this by adding NOREPL_ as a prefix to our intermediate tables. This approach looked promising on paper, but we ran into roadblocks pretty quickly.
Roadblock 1: SBR and RBR
When it comes to MySQL replication, there are 2 out-of-the box ways of doing it, SBR (statement-based replication) and RBR(row-based replication).
SBR works as its name suggests, which involves replaying the SQL statements run on the master, on the replica.
RBR works by applying the modifications done to each row by a MySQL statement on the master to the replica. This means the if, say an UPDATE, modified 10 million records, then the changes to each record will be saved to the binlog, relayed to, and then applied to the replica. This approach, although it looks inferior to SBR, has its benefits https://dev.mysql.com/doc/refman/8.0/en/replication-sbr-rbr.html
Now, coming to the roadblock, we were running MySQL replication in SBR mode and since we were ignoring the intermediate tables, we ran into the problem of not having the intermediate tables on the replica from which MySQL was supposed to create the final table! But, on prototyping with RBR, we didn’t run into this problem since the insert changes were recorded in the binlog. We wanted to continue to use SBR due to the reduced data generation and hence had to find a way around this.
To resolve this problem, I took advantage of the fact that for certain cases, when MySQL operates in SBR mode, it has to fall back to RBR to correctly replicate a change, for example, functions like rand(), version() etc. are such examples. This is due to the inherent non-determinism of the functions (explained in more detail here https://dev.mysql.com/doc/refman/8.0/en/replication-sbr-rbr.html ). So to work around this roadblock, we maintain 2 identical tables. The first table, let’s call it the staging table IS NOT replicated, and the second table, let’s call it the production table IS replicated. We create the production table from the staging table by simply copying data while using one of the non-deterministic functions to trick MySQL into using RBR. This eliminates the need for the staging table to be present on the replica.
The result was this template for copying data from the stage tables to the analytics (aka production) tables:
CREATE TABLE production_analytics_table AS
SELECT * FROM NOREPL_stage_table
WHERE VERSION() IS NOT NULLThis tricked MySQL to switch to RBR just for creating the production table hence giving us the benefits of both modes.
Roadblock 2: Weird behaviors and other hard-to-maintain code
This worked fine while prototyping but we still kept running into errors where MySQL complained that the table didn’t exist on the replica for a query for one of the procedures even though the table was ignored. This is something we weren’t able to explain. Also, updating all procedures to use the NOREPL_ prefix was introducing a lot of noise into the code as the procedures were now splattered with NOREPL_ everywhere. My colleague Akshay Chikane chipped in that they use SQL_LOG_BIN to disable binary logging when restoring DBs and this was the silver bullet.
This variable did exactly what we needed without polluting the existing procedures. All we needed to do was create a logical boundary in the procedure, one where bin logging was disabled and intermediate tables were created along with the final stage table and another where bin logging was enabled and the data from the staging table was copied to the production table that would be used for analytics.
Chaper 4: Putting it all together
Given our findings, we set out to update our procedures by making the following change.
Divide the procedure into two logical parts, in the first part, we disable bin logging by setting SQL_LOG_BIN to 0 and focus on creating the table that will be used for analytics, the resulting table will be the staging table. In the second part, we re-enable bin logging and copy the data from the staging analytics table into the production table.
The following code was tested on MySQL 8.0.28
-- consider a table called orders (order_id, customer_id, product_id, profit)
-- with a billion rows and we want to derive a table called
-- product_analytics(product_id, revenue) which records the total revenue
-- generated by a product
-- the vanilla procedure would look something like this
CREATE PROCEDURE create_product_analytics ()
BEGIN
START TRANSACTION;
-- create the intermediate table
CREATE TABLE
stage_analytics_table AS
SELECT
product_id,
SUM(profit)
FROM
orders
GROUP BY
product_id;
-- rename expected by users
DROP TABLE IF EXISTS product_analytics;
RENAME TABLE stage_analytics_table TO product_analytics;
COMMIT;
ENDWith the above-discussed optimizations, the procedure will look something like this
CREATE PROCEDURE create_product_analytics ()
BEGIN
-- PART 1: disable logging to binlog
SET SQL_LOG_BIN = 0;
START TRANSACTION;
-- create the stage analytics table
CREATE TABLE
stage_analytics_table AS
SELECT
product_id,
SUM(profit)
FROM
orders
GROUP BY
product_id;
COMMIT;
-- PART 2:
-- enable bin logging and copy the contents of the
-- stage table into the production analytics table
SET SQL_LOG_BIN = 1;
DROP TABLE IF EXISTS product_analytics;
CREATE TABLE
product_analytics AS
SELECT
*
FROM
stage_analytics_table
WHERE
VERSION() IS NOT NULL;
ENDThe clause VERISON() IS NOT NULL should evaluate to true for every MySQL version and also force MySQL to fall back to RBR replication.
The above example is simplified and can be extended to create multiple production tables. The only thing that needs to be kept in mind is that all intermediate tables and calculations go in the first part and in the second part we limit ourselves only to copying from stage to production tables.
Chaper 4: Pitfalls and conclusion
There are some things to be aware of while going for this approach.
- Setting
SQL_LOG_BINrequires system variable privileges, so the creator/editor of the procedure must have them. A possible workaround for a user who does not have this permission would be to create a standalone procedure that does just this with the relevant permissions, this can then be called by any user with procedure execution privileges - The variable needs to be handled carefully, for example, if an error were to throw by a statement and handled, it is possible that bin logging is not enabled again for later statements (the writer might’ve forgotten to re-enable logging) which needs to be replicated hence leading to loss of data. This depends on how MySQL deals with the replication of non-deterministic functions. Any changes to this implementation in future versions might lead to unexpected results.
- Due to switching to RBR, there will be an increase in the size of the binlog which translates to increased disk usage and increased N/W usage which will translate to increased costs. This is something that will vary based on the final size of the analytics tables. In our case, the binlogs size was on average 4-5 GB in size. This could be potentially tackled by enabling binlog compression that MySQL provides out of the box https://dev.mysql.com/doc/refman/8.0/en/binary-log-transaction-compression.html
To conclude, after applying just this (we are yet to break up transactions into smaller chunks), we saw an extremely good improvement in replica lag times as shown by the image above. This was due to time-consuming intermediate calculations not being performed again on the replica and limiting ourselves to only copying the production analytics tables.
Happy lag improving !